





搜索引擎到底是如何工作
发布:zhubinbin | 发布时间: 2012年12月20日从事seo工作就必须要了解搜索引擎原理,而我们做为一个称职的seo优化人,搜索引擎的守护者,不得不对它的运行规律、工作原理、习性、优缺点做了解,同时也不是了解理论就可以,还需要不断地实践,通过实践得真理,通过实践得到经验。那么搜索引擎到底是如何工作的呢?下面就由郑州seo为你做详细解说:
第一、搜索引擎爬行抓取
1)网与网认为爬行抓取是搜索引擎工作最重要的一部分,爬取网页回来分析,我们也应该知道我们在百度进行搜索时,基本是以秒来获得结果的,在如此讯速的时间里得到自己想要的结果,可见搜索引擎是事先做好这部分工作的,如果不然,那么想想每次搜索将要花多少时间与精力,其实按照网与网的理解来说,可以分为三小部分:
1、批量抓取所有网页,这种技术的缺点是浪费带宽,时效性不高。
2、增量收集,在前者的基础上进行技术改进,爬取更新的网页,并删除掉重复的内容以及无效的链接。
3、主动提交地址到搜索引擎,当然这种主动提交的方式被认为是审核期加长,这在部分seo资深人员看来是这样。
2)在链接爬取的过程中通常有两种方式我们需要理解,现在我们来了解一下深度优先以及广度优先
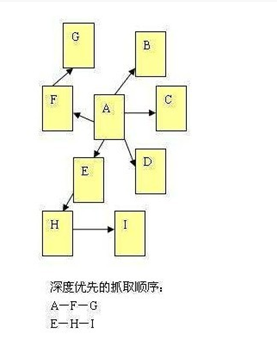
1、深度优先
蜘蛛从顶级A开始抓取,比如先从A FG,再从AEHI,依次类推。
 |
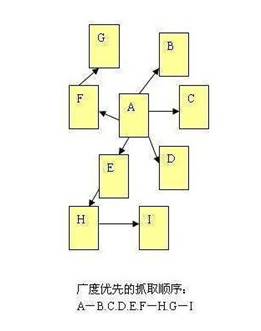
2、广度优先
主要指蜘蛛在一个页发现多个链接,先爬取所有第一层,然后接着是第二层,第三层……依次类推。
 |
但总的来说,无论是哪种爬行,目的都是让搜索引擎蜘蛛减少工作量,尽快完成抓取工作。
3)针对重复网页,我们需要访问列,同时也需要收集重要网页的机制
1、对于搜索引擎而言,如果重复爬取一些网页,不公浪费带宽,而且也不能增强时效性。所以搜索引擎需要一种技术来实现避免重复网页的出现。目前,搜索引擎可以用已访问列表以及未访问表来记录这个过程,这样极大的减少了搜索引擎的工作量。
2、重要的网页需要重点收录,因为互联网就像大海,不可能搜索引擎什么都抓取,所以需要采用不同的策略来收集一些重要的网页,主要可以通过几方面来实现,比如:目录越小有利于用户体验,节省蜘蛛爬行时间;高质量外链增加网页权重;信息更新及时,提高搜索引擎的光顾率;网站内容高质量,高原创。
第二、预处理是搜索引擎原理的第二步
1、把网页爬取回来,就需要多个处理阶段,其中之一就是关键词提取,把代码爬取下来,去掉比如CSS,DIV等标签,把这些对排名无意义的统统去除掉,剩下的是用于关键词排名的文字。
2、去除停用词,有些专家也称之为停止词,比如我们常见的:的、地、得、啊、呀、哎等无意义词。
3、中文分词技术,基于字符串匹配的分词方法以及统计分词方法。
4、消除噪声,把网站上的广告图片、登录框之类的信息去队掉。
5、分析网页,建立倒排文件方法
 |
本文由郑州seo整理发布!!!
- 相关文章:
图片img标签alt与title属性 (2012-12-20 22:28:54)
微博上@人发喜帖,你见过吗? (2012-12-20 22:28:16)
微博新应用 (2012-12-20 22:27:50)
网站优化前期工作 (2012-12-20 22:27:30)
如何建设外贸网站 (2012-12-20 22:26:54)
seo工作者必备能力 (2012-12-20 22:26:26)
中小企业如何低成本做网络推广 (2012-12-20 22:26:6)
如何打造高点击博客 (2012-12-20 22:25:38)
seo博客是否还能打造个人品牌 (2012-12-20 22:25:5)
网站内容和权重之间的关系 (2012-12-19 23:11:28)
发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。